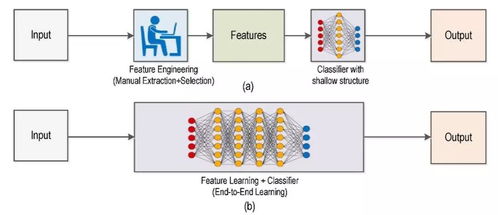
深度学习已成为计算机视觉领域的核心技术,尤其适用于目标检测和图像分割等任务。本文将介绍这两个关键任务的基本原理、应用场景及实施步骤。
一、目标检测
目标检测旨在识别图像中特定物体的位置和类别。深度学习模型通过特征提取和区域提议实现高精度检测。
常用模型包括:
- R-CNN系列(如Faster R-CNN):通过区域提议网络(RPN)生成候选框,再分类和回归。
- YOLO(You Only Look Once):将检测视为回归问题,实现端到端快速处理。
- SSD(Single Shot MultiBox Detector):结合多尺度特征图,平衡速度与精度。
实施步骤:
- 数据准备:收集标注数据(如COCO、PASCAL VOC数据集)。
- 模型选择:根据需求(如实时性、精度)选取合适架构。
- 训练优化:使用迁移学习微调预训练模型,增强泛化能力。
- 部署应用:集成到嵌入式设备或云平台,用于安防、自动驾驶等场景。
二、图像分割
图像分割将图像划分为语义区域,分为实例分割和语义分割。
常用模型:
- U-Net:编码器-解码器结构,适用于医疗影像分割。
- Mask R-CNN:扩展Faster R-CNN,添加掩码分支以生成像素级标签。
- DeepLab系列:采用空洞卷积和ASPP模块,捕获多尺度上下文信息。
实施步骤:
- 数据预处理:对图像和掩码进行增强(如旋转、缩放)。
- 模型训练:使用交叉熵损失函数优化分割精度。
- 后处理:应用CRF(条件随机场)细化边界。
- 应用领域:医学诊断(如肿瘤分割)、自动驾驶(道路识别)等。
技术服务支持:
为保障项目成功,需提供以下服务:
- 数据标注工具与流程设计。
- 模型定制与超参数调优。
- 硬件加速(如GPU集群)与边缘部署方案。
- 持续监控与模型更新机制。
总结,深度学习通过端到端学习显著提升了计算机视觉任务的性能。结合具体业务需求,选择合适模型并优化流程,可高效实现目标检测与图像分割的应用落地。